Vector.dev 日志写入Apache Doris 踩坑记录
最近研究日志采集技术选型的时候了解到了vector这个采集工具,据说是rust写的比filebeat之类快很多,而且开源许可也比elk技术栈那些靠谱一点,于是想试验一下采集工作中的sdk节点日志写入到doris集群里。
安装vector
vector的官网列出了非常多的安装方式,由于是内网机器是centos7.6且无法连接互联网,所以一键脚本不能用,一开始打算用rpm包安装。使用rpm -i 命令安装时报错glibc版本不够,这个是真没办法,只能按照指引去github下载musl包,这种包不需要系统的额外依赖,可以直接运行。
采集日志
安装好之后,先试着采集日志到console,看一下能否正确采集日志:
执行 /vector/vector/bin/vector --config /vector/vector/config/sdk.toml
data_dir = "/vector/vector/data"
[sources.log_source]
type = "file"
include = ["/jtcn-sdk/jtcn-sdk/logs/*.log"]
read_from = "beginning"
[transforms.parse_logs]
type = "remap"
inputs = ["log_source"]
source = '''
parsed, err = parse_regex(.message, r'\[(?P<thread>[^\]]+)\] \[(?P<level>[^\]]+)\] (?P<timestamp>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}) (?P<java_method>[^(]+)(?:\([^)]*\))? : (?P<message>.+)')
if err == null {
.thread = parsed.thread
.level = parsed.level
.timestamp = parsed.timestamp
.java_method = parsed.java_method
.log_message = parsed.message
.timestamp, err = format_timestamp(now(), "%Y-%m-%d %H:%M:%S")
del(.message)
}
'''
[sinks.console_sink]
type = "console"
inputs = ["parse_logs"]
encoding.codec = "json"
source表示日志的来源,类型是file,从目录采集日志文件。
transform表示日志的提取与转化,这里采用正则表达式来提取日志列。
sink表示写入目的,目前是输出到控制台,后面需要改成要写入的位置。
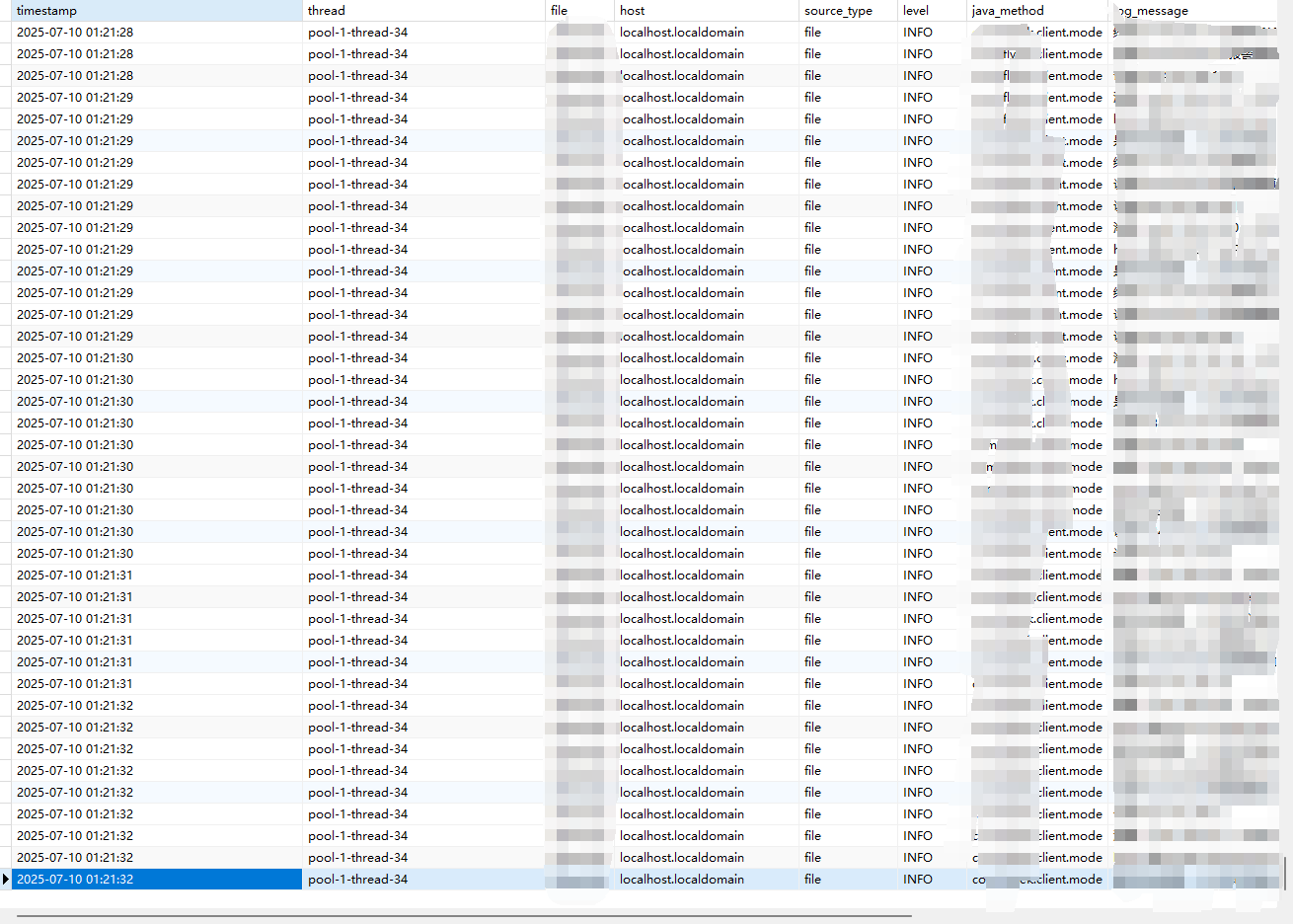
控制台可以正常输出日志,说明正则解析成功了,此时就可以准备doris的目标表,准备写入。
CREATE TABLE `sdk_log` (
`timestamp` datetime NOT NULL COMMENT "事件发生时间",
`thread` varchar(128) NULL COMMENT "日志来源线程",
`file` varchar(256) NOT NULL COMMENT "日志路径",
`host` varchar(256) NOT NULL COMMENT "日志来源",
`source_type` varchar(256) NOT NULL COMMENT "来源类型",
`level` varchar(32) NULL COMMENT "日志级别",
`java_method` varchar(512) NULL COMMENT "调用的方法",
`log_message` text NULL COMMENT "解析后的日志消息"
) ENGINE=OLAP
DUPLICATE KEY(`timestamp`, `thread`)
DISTRIBUTED BY HASH(`thread`) BUCKETS 16
PROPERTIES (
"replication_allocation" = "tag.location.default: 3",
"min_load_replica_num" = "-1",
"is_being_synced" = "false",
"storage_medium" = "hdd",
"storage_format" = "V2",
"inverted_index_storage_format" = "V1",
"light_schema_change" = "true",
"disable_auto_compaction" = "false",
"enable_single_replica_compaction" = "false",
"group_commit_interval_ms" = "10000",
"group_commit_data_bytes" = "134217728"
);;写入日志
然而事情并没有这么简单,vector的sink不支持doris,甚至不支持mysql(doris兼容mysql语法),但是doris支持http写入,也就是通过stream load的方式来写入,vector也是支持http sink的。经过一番调整之后,向doris fe写入json的配置写好了,但是经过测试,vector还是报错,307 重定向无法完成。原因是doris fe会先接受来自客户端的请求,然后自动分配告诉客户端重定向写入到be,这样才能实现多副本和负载均衡的功能。但是呢,vector似乎并不支持3xx类型的响应,直接就报失败了。根据doris官方的说法,其实通过be的http接口也可以直接写入,但这样就没有多副本了,若某个be宕机就没法用了,这个方案pass。
第二种想到的方案是使用kafka来过渡一下。vector支持kafka的sink,doris也支持routine load从kafka消费数据来写入,业务也有一套kafka集群,正好用kafka来做中间层。
data_dir = "/vector/vector/data"
[sources.log_source]
type = "file"
include = ["/jtcn-sdk/jtcn-sdk/logs/*.log"]
read_from = "beginning"
[transforms.parse_logs]
type = "remap"
inputs = ["log_source"]
source = '''
parsed, err = parse_regex(.message, r'\[(?P<thread>[^\]]+)\] \[(?P<level>[^\]]+)\] (?P<timestamp>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}) (?P<java_method>[^(]+)(?:\([^)]*\))? : (?P<message>.+)')
if err == null {
.thread = parsed.thread
.level = parsed.level
.timestamp = parsed.timestamp
.java_method = parsed.java_method
.log_message = parsed.message
.timestamp, err = format_timestamp(now(), "%Y-%m-%d %H:%M:%S")
del(.message)
}
'''
[sinks.kafka_sink]
type = "kafka"
inputs = ["parse_logs"]
bootstrap_servers = "xxx:xxx:xxx:xxx:xxxx"
topic = "sdk_log"
compression = "gzip"
[sinks.kafka_sink.encoding]
codec = "json"
[sinks.kafka_sink.librdkafka_options]
"security.protocol" = "SASL_PLAINTEXT"
"sasl.mechanism" = "GSSAPI"
"sasl.kerberos.service.name" = "kafka"
"sasl.kerberos.principal" = "[email protected]"
"sasl.kerberos.keytab" = "/config/user.keytab"
[sinks.kafka_sink.batch]
max_events = 1000
timeout_secs = 5但是,又遇到了一个问题,写入还是报错,显示不支持GSSAPI,但是文档里是说明支持的,vector的kafka是使用librdkafka这个库来连接的,通过透传参数的方式来连接Kerberos认证的kafka。去github issue里面搜索了一下,也有人遇到这种情况,原因是musl或者arm的包,里面没编译对于GSSAPI这块的支持。我也是服了,写个日志能这么费劲,还好业务里面还有个没认证的单机kafka,最后通过这种方式,也是通过routine load成功写入到了doris。
data_dir = /vector/vector/data"
[sources.log_source]
type = "file"
include = ["/jtcn-sdk/jtcn-sdk/logs/*.log"]
read_from = "beginning"
[transforms.parse_logs]
type = "remap"
inputs = ["log_source"]
source = '''
parsed, err = parse_regex(.message, r'\[(?P<thread>[^\]]+)\] \[(?P<level>[^\]]+)\] (?P<timestamp>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}) (?P<java_method>[^(]+)(?:\([^)]*\))? : (?P<message>.+)')
if err == null {
.thread = parsed.thread
.level = parsed.level
.timestamp = parsed.timestamp
.java_method = parsed.java_method
.log_message = parsed.message
.timestamp, err = format_timestamp(now(), "%Y-%m-%d %H:%M:%S")
del(.message)
}
'''
[sinks.kafka_sink]
type = "kafka"
inputs = ["parse_logs"]
bootstrap_servers = "xxx:9092"
topic = "sdk_log"
compression = "none"
[sinks.kafka_sink.encoding]
codec = "json"
[sinks.kafka_sink.batch]
max_events = 1000
timeout_secs = 5doris的routine load配置,配合前面的doris 建表语句使用
CREATE ROUTINE LOAD log.sdk_log ON sdk_log
COLUMNS(timestamp, thread, file, java_method, host, source_type, level, log_message)
PROPERTIES
( "format"="json",
"desired_concurrent_number"="3",
"max_batch_interval" = "10",
"max_batch_rows" = "300000",
"max_error_number"="10000",
"max_batch_size" = "209715200",
"strict_mode" = "false"
)
FROM KAFKA
(
"kafka_broker_list" = "xxx:9092",
"kafka_topic" = "sdk_log",
"property.group.id"= "doris_sdk_log"
);